
第3話 ノンパラメトリック最適化の難しさ その2「時間計算量」
前回までに、ノンパラメトリック最適化とは数学的には関数を対象とした最適化で、実際には有限要素モデルの規模(節点数、要素数)と同程度の数の設計変数を求める問題になることを説明しました。 この記事では、そのような問題を解くための最適化アルゴリズムについて解説します。
*****
まず、時間計算量という概念を導入しましょう。
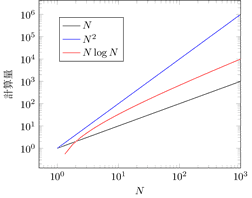
時間計算量は \(O(\cdot)\)という表記を使います。
これを使って計算時間がデータの数に対してどのように増加するのかを表します。
コンピュータープログラミングを勉強した方は分かると思いますが、\(N\) 個のデータの並べ替えを行うアルゴリズムであるクイックソートアルゴリズムの時間計算量は、平均的に \(O(N \log N)\) であると言われます。
一方、同じデータの並べ替えを行うアルゴリズムでもバブルソートアルゴリズムの時間計算量は、平均的に \(O(N^{2})\) であると言われます。
これは、クイックソートの計算時間がデータ数 \(N\) の増加に対して \(N \log N\) 倍で増加するのに対して、バブルソートは \(N^{2}\) 倍で増加する、ということを表しています。
増加の度合いはクイックソートの方が穏やかです。
もし、あるデータ数においてクイックソートとバブルソートが同程度の計算時間、あるいはバブルソートの方が速かったとしても、データ数が十分に大きくなるとクイックソートが必ず有利になる、ということが時間計算量から予測できます。
最適化問題を解き最適解を求めるためのアルゴリズムが「最適化アルゴリズム」です。
最適化アルゴリズムでは、多数の試行を行いながら設計変数を最適解に近づけていったり、最適解を得るための情報を収集したりします。
構造最適化の場合、その試行を行う度に有限要素解析を実行する必要があり、通常はこの計算時間が全体の解析時間の大半を占めます。
従って、なるべく少ない試行で最適解に辿り着く最適化アルゴリズムが重要です。
ノンパラメトリック最適化の場合、試行回数が求めるべき設計変数の数 \(N\)(=探索すべき空間の次元の大きさ)に対してなるべく大きくならないアルゴリズムが求められます。
さらに言えば \(N\) に依存しない時間計算量 \(O(1)\) のアルゴリズムが理想的です。
最適化アルゴリズムには様々なものがあります。 それぞれの最適化アルゴリズムについて、探索すべき空間の次元 \(N\) と試行回数との関係は必ずしも明確ではありませんが、ここでは三つのカテゴリーに分類して説明します。
- 遺伝的アルゴリズム(GA)に代表されるメタヒューリスティクスと呼ばれるカテゴリーのアルゴリズム
試行回数は経験的に \(O(N^{2})\) 程度と言われます。 このカテゴリーでは汎用性が重視されますが、汎用性を失わない範囲では \(O(N^{2})\) を大きく下回ることは難しいと思われます。
- 応答曲面法に代表されるような多数の試行に基づいて最適解を予測するアルゴリズム
少なくとも各次元について 1 回の試行が必要なので、少なくとも試行回数は \(O(N)\) になります。 このカテゴリーの手法では、直交表を利用して試行回数を減らすというアイデアが良く利用されますが、直交表は総当り(\(O(\exp(N))\))を \(O(N)\) に減らすのが目的で利用されるのであって、直交表を利用しても \(O(N)\) を下回ることはありません。
- 勾配法に代表される「感度」を使ったアルゴリズム
「感度」とは目的関数(あるいは制約関数)を設計変数で微分したものです。 数値微分を使って感度を計算してしまうと応答曲面法に近い方法(\(O(N)\))になってしまいますので、感度の計算は効率的に行う必要がありますが、いくつかの条件が整えば試行回数を \(O(1)\) にすることができます。
以上より、ノンパラメトリック最適化では \(N\) が極めて大きいことを考えると、感度を使ったアルゴリズムが有利だということが分かります。 実際、ノンパラメトリック最適化に分類される最適化手法は数多く提案されてきましたが、その中で成功を収めたと言える手法は全て感度を使っていると言っても過言ではありません。 逆に言えば、ノンパラメトリック最適化では適用できるアルゴリズムが感度を使ったものに制限される、と言えるかもしれません。
「\(H^{1}\) 勾配法」もその名の通り勾配法の一つで、感度を使ったアルゴリズムのカテゴリーに入る手法です。 勾配法についてはこの連載の中で詳しく解説していきます。 感度とその計算方法についてもその時に改めて説明します。
*****
最後に、OPTISHAPE-TS が試行回数 \(O(1)\) の最適化アルゴリズムを使っていることを簡単な解析例で確認してみましょう。
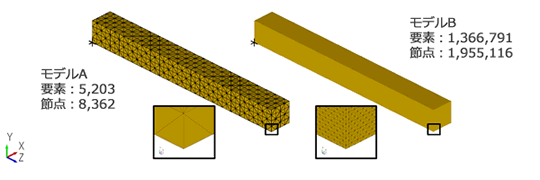
先端に荷重を受ける片持ち梁のモデルを二種類用意しました。 モデルAは5,203要素、8,362節点で、静弾性解析1回あたりの計算時間は1~2秒でした。 モデルBは1,366,791要素、1,955,116節点で、静弾性解析に要する計算時間は1時間25分前後でした。 これらのモデルの間には規模(節点数、要素数)で200倍以上、計算時間では3000倍以上の違いがあります。
これらのモデルそれぞれについて、梁の全長と厚さが変化しないように形状拘束を行って、さらに図の \(X\) 方向に等断面形状変動制限を適用した上で、OPTISHAPE-TS のノンパラメトリック形状最適化機能を使って体積制約、コンプライアンス最小化解析を行いました。 この問題設定では、1回の試行で静弾性解析を1回実行する必要があります。
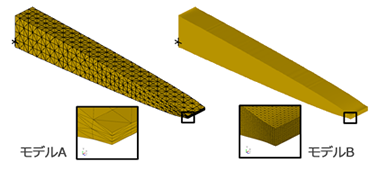
いずれのモデルも、最適化繰り返し回数50回(最適化前後も含めて試行回数は51)で同様の結果形状が得られました。 最適化解析全体の計算時間は、モデルAが109秒、モデルBが約72時間でした。 いずれも静弾性解析51回分の計算時間にほぼ等しく、それ以外の処理に要する時間は極めて短いことが分かります。
最適化過程における目的・制約関数の履歴を確認してみましょう。
いずれのモデルでも体積(赤線)は制約値(100%)を維持したままで、コンプライアンス(青線)が約60% にまで低下していることが分かります。
モデルBの方が、最初の数回の繰り返しで目的関数の低下が穏やかですが、概ねモデルAとモデルBで同じような履歴で最適解に収束していることが分かります。
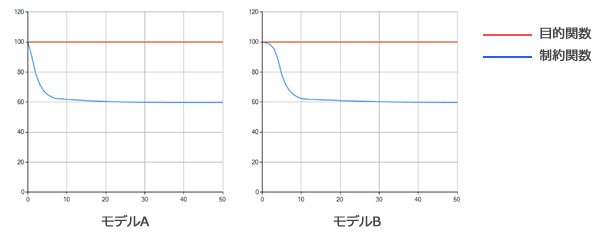
以上より、OPTISHAPE-TS の最適化アルゴリズムでは最適解に至るまでに必要な試行回数がモデルの規模に依存しない、つまり \(O(1)\) であることが確認できました。
*****
次回は、別の視点でノンパラメトリック最適化の難しさについて解説します。
★ご意見・ご感想はこちらへ★
![]() https://www.quint.co.jp/cgi-bin/qrepo-impr.cgi
https://www.quint.co.jp/cgi-bin/qrepo-impr.cgi